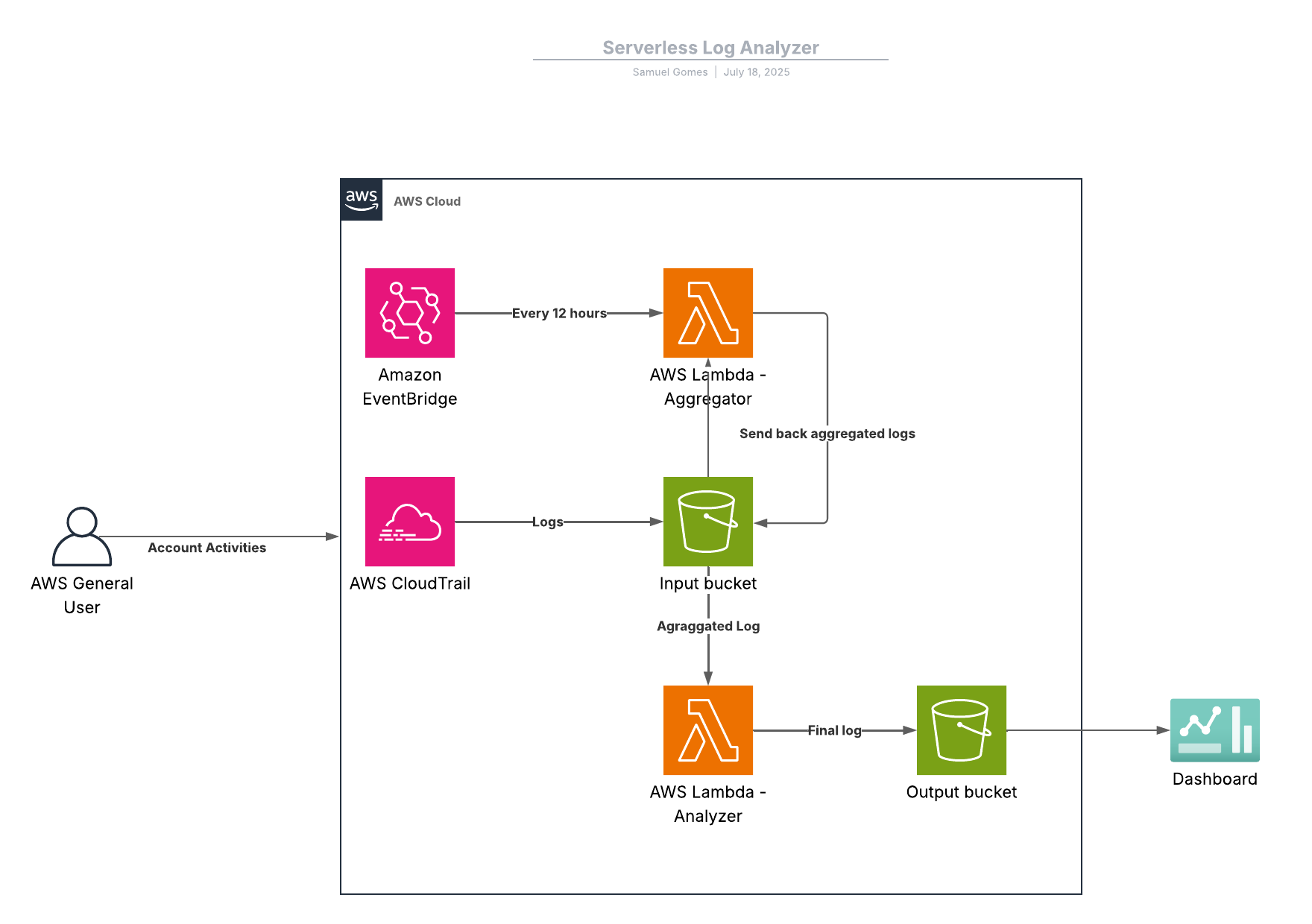
This project demonstrates the use of AWS to generate and analyze logs. It was designed to provide automated insights into AWS account activities through a serverless architecture that monitors, processes, and analyzes CloudTrail logs in real-time. The system automatically captures all AWS API calls and management events via CloudTrail, aggregates daily log files for efficient processing, and generates comprehensive statistical reports about resource usage patterns, security events, and operational activities. The solution uses Lambda functions, S3 storage, and EventBridge to create a cost-effective, scalable log analysis system that requires no infrastructure management while providing comprehensive visibility into AWS account activities.
The infrastructure is implemented through a modular architecture using Terraform, which provisions the following AWS components organized into 5 main modules.
Modules
S3 Module: This module is responsible for creating the storage infrastructure with two S3 buckets. It configures the input bucket to receive CloudTrail logs and the output bucket for processed insights. Both buckets are secured with versioning enabled, AES256 encryption, and complete public access blocking to ensure data protection and compliance.
IAM Module: The Identity and Access Management (IAM) module manages security permissions for the Lambda functions. It creates a dedicated execution role with precise permissions for S3 operations (read, write, delete) on both buckets and CloudWatch logging capabilities, following the principle of least privilege for enhanced security.
Lambda Module: This module handles the serverless compute functions that process the logs. It deploys two Python 3.11 Lambda functions - the Analyzer for processing aggregated logs and generating insights, and the Aggregator for consolidating daily log files. The module also configures S3 event triggers and proper permissions for seamless integration.
CloudTrail Module: The CloudTrail module sets up comprehensive AWS account auditing and logging. It configures a multi-region trail that captures management events, global service events, and S3 data events, automatically delivering all logs to the input S3 bucket with appropriate bucket policies for secure log storage.
EventBridge Module: This module manages the automated scheduling system for log processing. It creates a CloudWatch Event Rule with a cron expression to trigger the Lambda Aggregator function every 12 hours, ensuring regular log consolidation and processing without manual intervention.
Inside each module, there is a main.tf file that defines the resources, a variables.tf file that defines the variables, and an outputs.tf file that defines the outputs, when needed.
S3 Module
This module is designed to create the storage infrastructure with two S3 buckets, one for input logs and one for output insights. The input bucket receives CloudTrail logs automatically, while the output bucket stores the processed JSON and CSV reports. Both buckets are configured with versioning enabled for change tracking, AES256 server-side encryption for data protection, and complete public access blocking to ensure security compliance.
Features
S3 Buckets: Creates two S3 buckets - an input bucket for receiving CloudTrail logs and an output bucket for storing processed insights and reports.
Versioning: Enables versioning on both buckets to maintain object history and provide rollback capabilities for data protection.
Encryption: Configures AES256 encryption by default on all objects stored in both buckets to ensure data security at rest.
Public Access Blocking: Implements comprehensive public access restrictions on both buckets, blocking all forms of public access including ACLs and bucket policies to prevent unauthorized access.
Resources
1. Buckets
Resource: aws_s3_bucket
bucket: The unique name identifier for the S3 bucket within AWS.
force_destroy: Whether to allow deletion of the bucket even when it contains objects.
tags: Assigns a name tag to the bucket for identification and resource management purposes.
This module is designed to create the security and access management infrastructure for the Lambda functions. It establishes a dedicated IAM role with precisely scoped permissions following the principle of least privilege. The role allows Lambda functions to interact with S3 buckets for log processing and CloudWatch for logging, while restricting access to only the necessary resources and actions required for the log analysis workflow.
Features
IAM Role: Creates a dedicated execution role specifically for Lambda functions with a trust policy that allows only the Lambda service to assume the role
IAM Policy: Attaches a policy to the role that grants the necessary permissions for the Lambda function to access the S3 bucket and CloudWatch logs.
Resources
1. IAM Role
Resource: aws_iam_role
name: The name of the IAM role.
assume_role_policy: The policy that allows the Lambda service to assume the role. It defines which services are allowed to assume the role, in this case, only the Lambda service.
This module is designed to create the serverless compute infrastructure for log processing and analysis. It establishes two specialized Lambda functions that handle different aspects of the log analysis workflow - one for aggregating daily logs and another for processing aggregated logs to generate insights. The module also configures the necessary triggers, permissions, and integrations to enable automatic execution based on S3 events and scheduled intervals.
Features
Lambda Aggregator Function: Deploys a Python 3.11 Lambda function that consolidates multiple daily log files into single aggregated files, designed to be triggered by EventBridge scheduling.
Lambda Analyzer Function: Creates a Python 3.11 Lambda function that processes aggregated CloudTrail logs and generates statistical insights, triggered automatically by S3 ObjectCreated events.
Lambda Permissions: Establishes proper permissions allowing S3 service to invoke the Lambda functions while maintaining security boundaries.
This module is designed to create comprehensive AWS account auditing and logging infrastructure. It establishes a multi-region CloudTrail that captures all management events, global service events, and S3 data events across the entire AWS account. The module automatically delivers all captured logs to the designated S3 input bucket and configures the necessary bucket policies to enable secure log storage while maintaining proper access controls for the CloudTrail service.
Features
CloudTrail Configuration: Creates a multi-region trail that monitors AWS account activities across all regions, including global services like IAM, Route53, and CloudFront to provide complete visibility. The CloudTrail also captures all management plane operations such as resource creation, deletion, and configuration changes for comprehensive account auditing.
S3 Integration: Automatically delivers all captured logs to the input S3 bucket, and establishes secure S3 bucket policies that grant CloudTrail service the minimum necessary permissions to write logs and read bucket ACLs while maintaining security boundaries.
Resources
1. CloudTrail Configuration
Resource: aws_cloudtrail
name: The name of the CloudTrail.
s3_bucket_name: The name of the S3 bucket to store the CloudTrail logs.
is_multi_region_trail: Whether the trail captures events from all AWS regions or just where it's created.
include_global_service_events: Whether to include events from global AWS services like IAM and STS.
enable_logging: Whether to enable logging.
event_selector: Configuration block that defines which types of events the trail should capture.
depends_on: Ensures the CloudTrail is created only after the specified dependencies are established.
bucket: The S3 bucket to configure the policy for.
policy: The JSON-encoded policy document that defines the permissions and access controls for the bucket, specifying who can perform what actions on the bucket and its objects.
This module is designed to create automated scheduling infrastructure for periodic log processing tasks. It establishes a CloudWatch Event Rule with cron-based scheduling that automatically triggers the Lambda Aggregator function every 12 hours to consolidate daily CloudTrail logs. The module configures the necessary event targets, permissions, and payload delivery to enable seamless integration between the scheduling service and the serverless compute functions..
Features
CloudWatch Event Rule: Creates an EventBridge rule that automatically triggers the Lambda analyzer function whenever new log files are uploaded to the input S3 bucket.
Lambda Target Configuration: Establishes the Lambda Aggregator function as the target for the scheduled events, with proper payload configuration including account ID for contextual processing.
EventBridge Permissions: Configures Lambda permissions to allow the EventBridge service to invoke the aggregator function while maintaining security boundaries and preventing unauthorized access.
Resources
1. CloudWatch Event Rule
Resource: aws_cloudwatch_event_rule
name: The unique name identifier for the EventBridge rule within the AWS account.
description: The description of the EventBridge rule.
schedule_expression: The cron or rate expression that defines when the rule should trigger, supporting both cron syntax and rate-based scheduling formats.
The main.tf file serves as the central configuration for deploying and managing the infrastructure on AWS using Terraform. It orchestrates the setup of the modules and resources previously defined, ensuring that all components are correctly provisioned and interconnected to form a cohesive infrastructure environment.
The Lambda Aggregator is a Python 3.11 serverless function designed to consolidate multiple CloudTrail log files from a single day into one aggregated file. This function is triggered by EventBridge every 12 hours and performs log consolidation, compression, and cleanup operations to optimize storage and prepare data for analysis.
Purpose
Consolidate multiple daily CloudTrail log files into a single aggregated file.
Reduce the number of individual files for efficient processing.
Cleanup original log files to optimize storage costs.
Prepare data for analysis by the analyzer function.
Full Code:
lambda-aggregator/handler.py
import boto3
import gzip
import json
from datetime import datetime
from io import BytesIO
s3 = boto3.client('s3')deflambda_handler(event, context):print("aggregator called") bucket_name ='samuellincoln-log-analyzer-input'# Calculate current date current_date = datetime.utcnow() year = current_date.strftime("%Y") month = current_date.strftime("%m") day = current_date.strftime("%d")# Create dynamic prefix prefix =f'AWSLogs/{event["account_id"]}/CloudTrail/us-east-1/{year}/{month}/{day}/'print(f"dynamic prefix: {prefix}") aggregated_data =[]# List objects in bucket with specified prefix response = s3.list_objects_v2(Bucket=bucket_name, Prefix=prefix)print(f"list_objects_v2 response: {response.get('Contents',[])}")for obj in response.get('Contents',[]):print(f"analyzing object: {obj}") key = obj['Key']print(f"analyzing key: {key}")if key.endswith('.json.gz')and'aggregated'notin key:# Read and decompress file obj_data = s3.get_object(Bucket=bucket_name, Key=key)with gzip.GzipFile(fileobj=BytesIO(obj_data['Body'].read()))as gz: log_content = json.load(gz) aggregated_data.extend(log_content['Records'])# Get current date and time to name the file now = datetime.utcnow() output_key =f"{now.strftime('%Y-%m-%d-%H:%M')}-aggregated.json.gz"print(f"will save to bucket with path: {prefix}{output_key}")# Compress and write aggregated file out_buffer = BytesIO()with gzip.GzipFile(fileobj=out_buffer, mode='w')as gz: gz.write(json.dumps({'Records': aggregated_data}).encode('utf-8'))# Save aggregated file to S3 s3.put_object(Bucket=bucket_name, Key=f"{prefix}{output_key}", Body=out_buffer.getvalue())# Delete old log filesfor obj in response.get('Contents',[]): key = obj['Key']print(f"will delete file: {key}")if key.endswith('.json.gz')and'aggregated'notin key: s3.delete_object(Bucket=bucket_name, Key=key)print("Logs aggregated and old logs deleted successfully")return{'statusCode':200,'body': json.dumps('Logs aggregated and old logs deleted successfully')}
Downloads each individual log file, decompresses gzip content in memory, extracts Records array from each file, and consolidates all records into a single array.
5. Output File Creation
lambda-aggregator/handler.py
# Get current date and time to name the filenow = datetime.utcnow()output_key =f"{now.strftime('%Y-%m-%d-%H:%M')}-aggregated.json.gz"print(f"will save to bucket with path: {prefix}{output_key}")# Compress and write aggregated fileout_buffer = BytesIO()with gzip.GzipFile(fileobj=out_buffer, mode='w')as gz: gz.write(json.dumps({'Records': aggregated_data}).encode('utf-8'))# Save aggregated file to S3s3.put_object(Bucket=bucket_name, Key=f"{prefix}{output_key}", Body=out_buffer.getvalue())
Generates a timestamp-based filename, compresses aggregated data using gzip, and uploads the consolidated file to S3 in the format YYYY-MM-DD-HH:MM-aggregated.json.gz.
6. Cleanup Operations
lambda-aggregator/handler.py
# Delete old log filesfor obj in response.get('Contents',[]): key = obj['Key']print(f"will delete file: {key}")if key.endswith('.json.gz')and'aggregated'notin key: s3.delete_object(Bucket=bucket_name, Key=key)
Deletes original individual log files while preserving the new aggregated file, optimizing storage costs and organization.
7. Results
The function completes successfully, consolidating logs and optimizing storage.
The Lambda Analyzer is a Python 3.11 serverless function designed to process aggregated CloudTrail log files and generate comprehensive statistical insights about AWS account activities. This function is triggered automatically by S3 ObjectCreated events when aggregated log files are uploaded, and it produces detailed reports in both JSON and CSV formats for further analysis.
Purpose
Process aggregated CloudTrail log files to extract meaningful insights.
Analyze AWS account activities and usage patterns.
Generate statistical reports on events, resources, regions, and user activities.
Export results in multiple formats (JSON and CSV) for dashboard integration.
Handler Code
lambda-analyzer/handler.py
import boto3
import json
import gzip
import os
from urllib.parse import unquote
from exporter import export_to_json, export_to_csv
from analyzer import process_logs
s3 = boto3.client("s3")deflambda_handler(event, context): bucket_name = event["Records"][0]["s3"]["bucket"]["name"]print(f"[+] Bucket name: {bucket_name}") key = event["Records"][0]["s3"]["object"]["key"]print(f"[+] Key: {key}") key = unquote(key) base_filename = os.path.splitext(key.split('/')[-1])[0] local_gz_path =f"/tmp/{key.split('/')[-1]}"print(f"[+] Local gz path: {local_gz_path}")print(f"[+] Downloading file from s3") s3.download_file(bucket_name, key, local_gz_path)print(f"[+] File downloaded from s3") local_json_path = local_gz_path.replace('.gz','')print(f"[+] Local json path: {local_json_path}")print(f"[+] Unzipping file")with gzip.open(local_gz_path,'rt')as gz_file:withopen(local_json_path,'w')as json_file: json_file.write(gz_file.read())print(f"[+] File unzipped")if os.path.exists(local_json_path):print(f"[+] JSON file created at {local_json_path}")else:print(f"[-] JSON file not found at {local_json_path}")if"aggregated"in base_filename: insights = process_logs(local_json_path) base_filename = base_filename.replace('-aggregated.json','') json_path =f"{local_json_path.rsplit('/',1)[0]}/{base_filename}-insights.json" csv_path =f"{local_json_path.rsplit('/',1)[0]}/{base_filename}-insights.csv" export_to_json(insights, json_path) export_to_csv(insights, csv_path) directory ='/'.join(key.split('/')[:-1]) new_key_json =f"{directory}/{base_filename}-insights.json" new_key_csv =f"{directory}/{base_filename}-insights.csv"print(f"[+] Uploading insights to output s3 in path {new_key_json} and {new_key_csv}") s3.upload_file(json_path,"samuellincoln-log-analyzer-output", new_key_json) s3.upload_file(csv_path,"samuellincoln-log-analyzer-output", new_key_csv)print(f"[+] Insights uploaded to s3")else:print(f"[-] File {base_filename} does not contain 'aggregated', skipping processing.")
The function is triggered automatically by S3 ObjectCreated events when new files are uploaded to the input bucket. It extracts bucket name and object key from the S3 event payload.
2. File Download and Path Setup
lambda-analyzer/handler.py
base_filename = os.path.splitext(key.split('/')[-1])[0]local_gz_path =f"/tmp/{key.split('/')[-1]}"print(f"[+] Local gz path: {local_gz_path}")print(f"[+] Downloading file from s3")s3.download_file(bucket_name, key, local_gz_path)print(f"[+] File downloaded from s3")
Downloads the triggered file from S3 to the Lambda's /tmp directory for local processing, and extracts the base filename for future use.
Validates that the file is an aggregated log file before processing. If valid, calls the analyzer module to process the logs and defines output paths for the insights files.
Processes the JSON log file to extract and count various metrics including event names, resource types, regions, source IPs, event types, event categories, and user identity types.
Exports the generated insights to both JSON (complete data structure) and CSV (event counts only) formats for different use cases and integrations.
7. Output Upload to S3
lambda-analyzer/handler.py
directory ='/'.join(key.split('/')[:-1])new_key_json =f"{directory}/{base_filename}-insights.json"new_key_csv =f"{directory}/{base_filename}-insights.csv"print(f"[+] Uploading insights to output s3 in path {new_key_json} and {new_key_csv}")s3.upload_file(json_path,"samuellincoln-log-analyzer-output", new_key_json)s3.upload_file(csv_path,"samuellincoln-log-analyzer-output", new_key_csv)print(f"[+] Insights uploaded to s3")
Uploads the generated insights to the output S3 bucket in the specified paths, completing the analysis process.
The Dashboard is an interactive visualization interface that transforms the processed AWS account activity data from the Lambda Analyzer into intuitive charts and metrics. This dashboard provides stakeholders with real-time insights into AWS usage patterns, security events, and operational trends through visual representations of event frequencies, regional distribution, user activities, resource utilization, and source IP analysis.